By Thisal De Silva Posted on
Blogger, software engineer and technologist Thisal de Silva on the workaround we used at WealthOS to maximise and facilitate our AWS Lambda Function usage. If you missed the previous intro to Lambda functions check it out here.
What was our problem?
AWS Lambda functions have a maximum execution time of 15 minute, and sometimes that “just ain’t enough”. Our platform covers a wide variety of middle and back-office functionality for a wealth manager.

We run batch operations such as generating quarterly bills or rebalancing multiple accounts (pots – in WealthOS lingo) to a portfolio. Serverless/lambda architecture encourages horizontal scalability by design, but running certain types of batch operations parallelly can result in an invalid output. Trying to run these operations in sequential order will simply take too long and result in the Lambda timing out. We had to design a solution where we can use the efficiency and lightweight nature of Lambdas while ensuring the correct completion of these long-running batch jobs.
We’ve ruled out the obvious solution
The go-to solution, when a serverless function’s execution time is not enough on a cloud environment, would be to introduce a separate K8 , AWS batch, ECS or an alternative form of an environment inside the cloud provider. However, we felt that introducing such an alternative for just one or two functional requirements would be contrary to our platform’s architectural ethos. And introducing a separate form of execution means more deployments and maintenance related overheads!
Breaking down the problem
Our problem consisted of two parts. First, performing a generic set of steps for any batch operation and second, a more specific set of actions for each functional requirement.
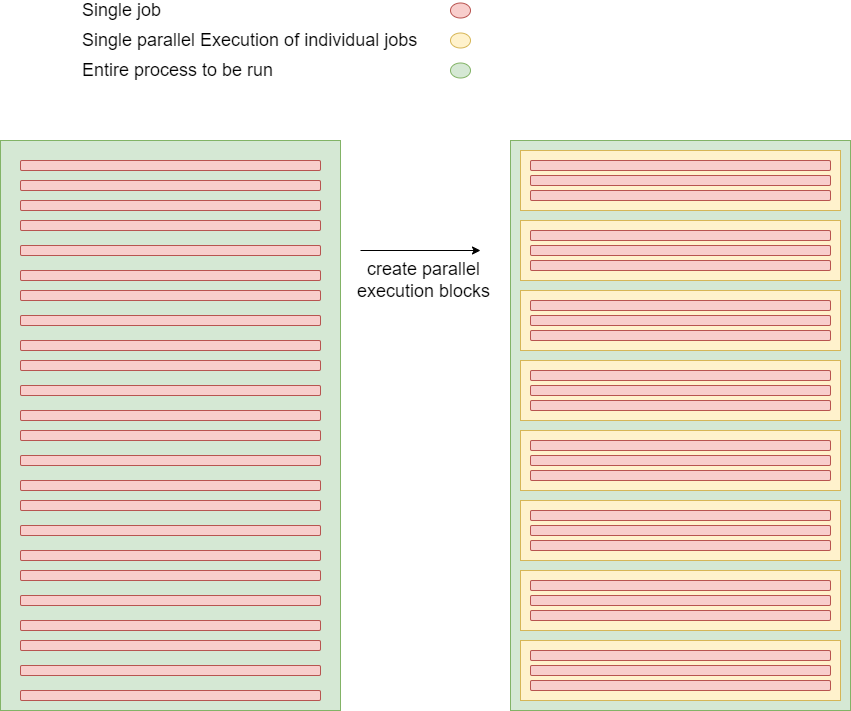
For example, let’s say our entire operation consists of 24 tasks, which involve some computations and, each task takes 1 – 3 minutes to calculate the final result and save the output to the database.
The entire job (green box) can be divided into smaller groups of execution blocks (yellow boxes) which contain individual jobs (coloured in red). Each of these yellow boxes will run sequentially.
So, our implementation requirement was to group a few operations together as a parallel unit of execution and run these parallel units sequentially. However, running these operations sequentially easily go beyond 15 minutes (sometimes even 30 minutes or more) due to the load involved – way above the maximum time allocated for a single lambda instance.
In the above example, if we consider the worst case, that is 3 minutes taken by each yellow box then we would only be able to run 5 of those boxes in a single lambda instance. (since maximum time for Lambda is 15 minutes and 15/3 = 5).
The WealthOS Team Solve
We needed a solution to this problem without drifting out of our core serverless inspiration.
Our study established that every batch operation can be divided into two parts – generic and specific. This allowed us to group a number of individual jobs that can be run in parallel (generic jobs) and separate what needs to be done in a single job (specific jobs) as per the relevant use case.
The single job will be implemented by each developer who is implementing that specific feature and will vary based on the feature being built. For the generic part of the operation we introduced the following framework – define parallel execution blocks (identified in yellow boxes above), run as many of these in a single lambda, and handover the remaining work to a new lambda before timing out. The diagram below explains this further.
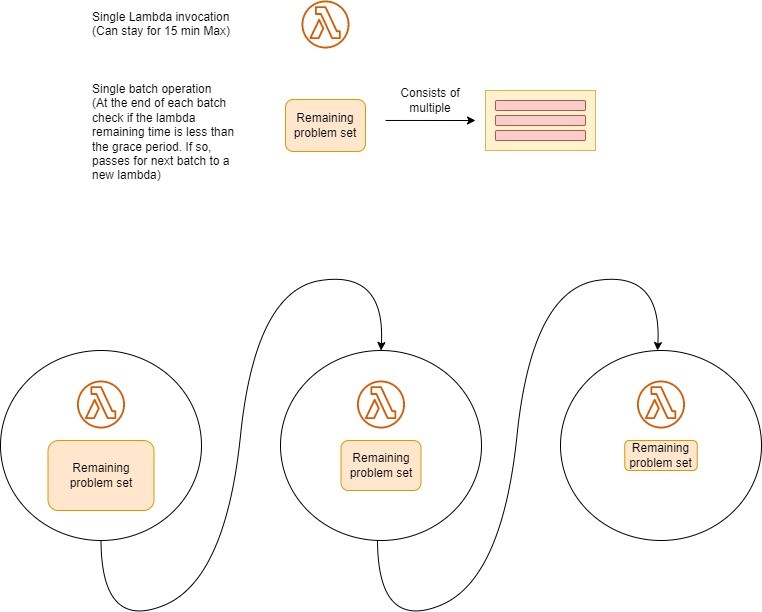
The pseudocode for the above generic part implementation has been shown below.
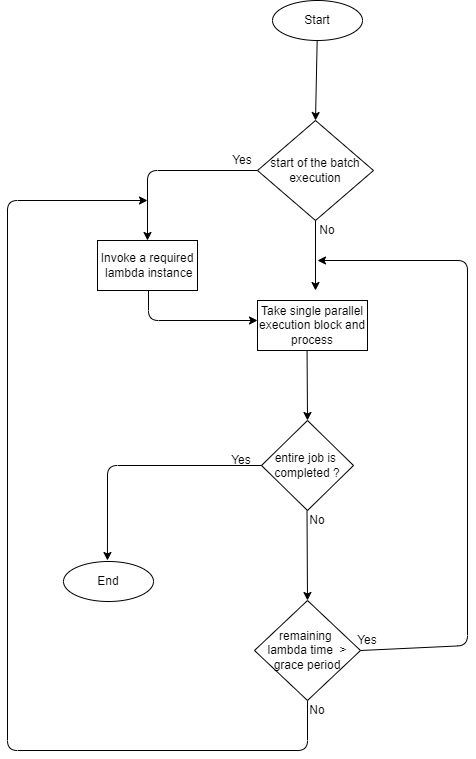
If you are a developer and are curious about the implementation details, give us a shout. The implementation draws inspiration from recursive programming principles. Ultimately, we were pleased that we identified a solution without incorporating any architectural erosion into the system. Hope you enjoyed reading this as much as I enjoyed writing it! Thank you 💙!